Brief Introduction of Label Propagation Algorithm
Table of Contents
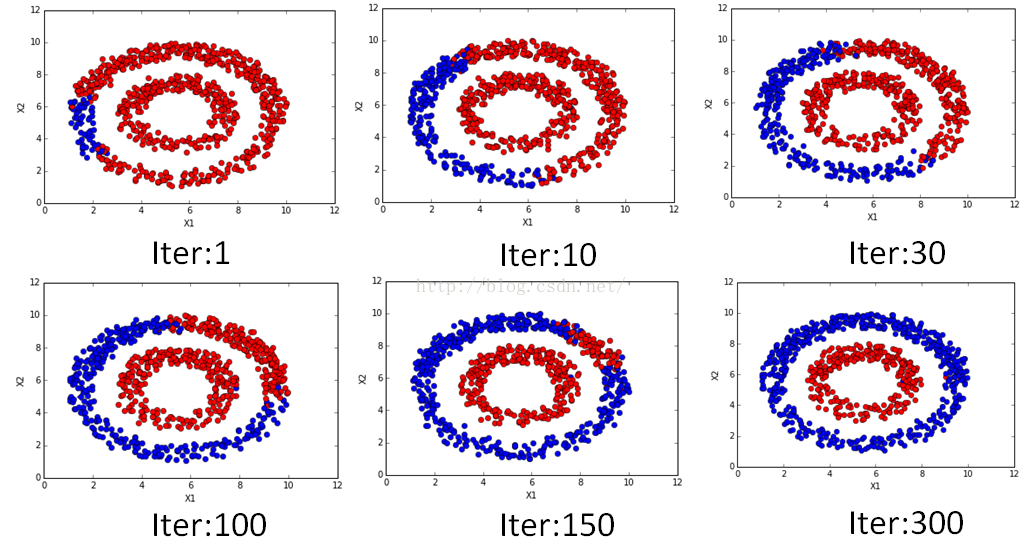
As I said before, I’m working on a text classification project. I use doc2vec to convert text into vectors, then I use LPA to classify the vectors.
LPA is a simple, effective semi-supervised algorithm. It can use the density of unlabeled data to find a hyperplane to split the data.
Here are the main stop of the algorithm:
- Let $ (x_1,y1)…(x_l,y_l)$ be labeled data, $Y_L = \{y_1…y_l\} $ are the class labels. Let \((x_{l+1},y_{l+u})\) be unlabeled data where \(Y_U = \{y_{l+1}…y_{l+u}\}\) are unobserved, usually \(l \ll u\). Let \(X=\{x_1…x_{l+u}\}\) where \(x_i\in R^D\). The problem is to estimate \(Y_U\) for \(X\) and \(Y_L\).
- Calculate the similarity of the data points. The most simple metric is Euclidean distance. Use a parameter \(\sigma\) to control the weights.
\[w_{ij}= exp(-\frac{d^2_{ij}}{\sigma^2})=exp(-\frac{\sum^D_{d=1}{(x^d_i-x^d_j})^2}{\sigma^2})\]
Larger weight allow labels to travel through easier.
- Define a \((l+u)*(l+u)\) probabilistic transition matrix \(T\)
\[T_{ij}=P(j \rightarrow i)=\frac{w_{ij}}{\sum^{l+u}_{k=1}w_{kj}}\]
\(T_{ij}\) is the probability to jump from node \(j\) to \(i\). If there are \(C\) classes, we can define a \((l+u)*C\) label matrix \(Y\), to represent the probability of a label belong to class \(c\). The initialization of unlabeled data points is not important.
- Propagate \(Y \leftarrow TY\)
- Row-normalize Y.
- Reset labeled data’s Y. Repeat 3 until Y converges.
In short, let the nearest label has larger weight, then calculate each label’s new label, reset labeled data’s label, repeat.