Retrieve Large Dataset in Elasticsearch
Table of Contents
It’s easy to get small dataset from Elasticsearch by using size and from. However, it’s impossible to retrieve large dataset in the same way.
Deep Paging Problem #
As we know it, Elasticsearch data is organised into indexes, which is a logical namespace, and the real data is stored into physical shards. Each shard is an instance of Lucene. There are two kind of shards, primary shards and replica shards. Replica shards is the copy of primary shards in case nodes or shards fail. By distributing documents in an index across multiple shards, and distributing those shards across multiple nodes, Elasticsearch can ensure redundancy and scalability. By default, Elasticsearch create 5 primary shards and one replica shard for each primary shards.
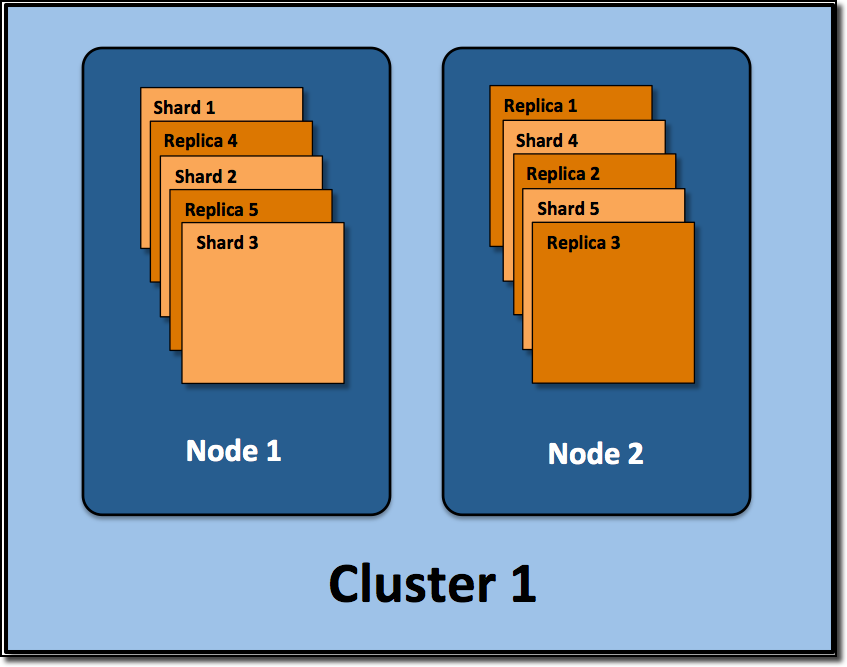
How to decide which shard should the document be distributed? By default, shard = hashCode(doc._id) % primary_shards_number. To make this stable, the number of primary shards cannot be change the index has been created.
Usually, the shards size should be 20GB to 40GB. The number of shards a node can hold is depending on the heap space. In general, 1GB heap space can hold 20 shards.
As data is store in different shards. If there are 5 shards, when doing this query:
GET /_search?size=10
Each shards will generate 10 search result, and send results to coordinate node. The coordinate node will sort 50 items, and result the first 10 result to user. However when query become this:
GET /_search?size=10&from=10000
Although we only need 10 items, each shards has to return the first 10010 result to coordinate node, and coordinate node has to sort 50050 items, this search cost lots of resource.
As deep paging is costly, Elasticsearch has restrict from+size less than index.max-result-window, the default value is 10000.
Scroll #
The search method has to retrieve and sort the result over and over again, because it does not know how to continue the search from previous position.
scroll is more efficient when retrieve large set of data.
For example:
POST /twitter/_search?scroll=1m
{
"size": 100,
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
and the returned result will contains a _scroll_id, which should be passed to the scroll API in order to retrieve the rest of data.
POST /_search/scroll
{
"scroll" : "1m",
"scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ=="
}
Scroll return the matched result at the time of the initial search request, like a snapshot, and ignore the subsequent changes to the documents(index, update or delete). The scroll=1m is used to tell how long should Elasticsearch keep the context. If there no following requests using the returned scroll_id, the scroll context will expire.
PS: In fact, when dealing the initial search request, scoll will cache all the matched documents’ id, then get the size document content in batches for each following requests.
Slice #
It’s also possible to split the scroll in multiple slices and consume them independently.
GET /twitter/_search?scroll=1m
{
"slice": {
"id": 0,
"max": 2
},
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
GET /twitter/_search?scroll=1m
{
"slice": {
"id": 1,
"max": 2
},
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
The above request contains split the slice into 2 parts by using max:2 parameter. These union of two requests’ data is equivalent to the result of a scroll query without slicing.
The slice of the document can be calculated by this formula: slice(doc) = hash(doc._id) % max_slice. This is quiet similar to the calculation of shards mentioned before. For example if slice is 4, and shards is 2. Then slices 0,2 are assigned to first shard and slices 1,3 are assigned to second shard.
When slices number is n, each matched documents use a n bitset to remember which slice it belongs to. So you should limit the number of sliced query you perform in parallel to avoid the memory explosion.
Getting hash(doc._id) is expensive. You can also use another numeric doc_value field to do the slicing without hash function. For instance:
GET /twitter/_search?scroll=1m
{
"slice": {
"field": "date",
"id": 0,
"max": 10
},
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
Query performance is most efficient when the number of slices is equal to the number of shards in the index. If that number is large (e.g. 500), choose a lower number as too many slices will hurt performance. Setting slices higher than the number of shards generally does not improve efficiency and adds overhead.
Search After #
Scroll is not suitable for real-time user requests. After Elasticsearch 5, Search After API is added. It’s similar to scroll but provides a live cursor. It uses the results from the previous page to retrieve the next page.
To use search after, the query must be sorted, and the following query also contains search_after=previous sort value.
For example, if the initial query is this:
GET twitter/_search
{
"size": 10,
"query": {
"match" : {
"title" : "elasticsearch"
}
},
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}
Then you have to extract the sort value of the last document, and pass it to search_after to get the next page result.
GET twitter/_search
{
"size": 10,
"query": {
"match" : {
"title" : "elasticsearch"
}
},
"search_after": [1463538857, "654323"],
"sort": [
{"date": "asc"},
{"tie_breaker_id": "asc"}
]
}