Time boundary in InfluxDB Group by Time Statement
These days I use InfluxDB to save some time series data. I love these features it provides:
High Performance
According to to it’s hardware guide, a single node will support more than 750k point write per second, 100 moderate queries per second and 10M series cardinality.
Continuous Queries
Simple aggregation can be done by InfluxDB’s continuous queries.
Overwrite Duplicated Points
If you submit a new point with same measurements, tag set and timestamp, the new data will overwrite the old one.
Preset Time Boundary
InfluxDB is well documented, but the group by time section is not very clear. It says it will group data by =preset time boundary. But the example it use is too simple and doesn’t explain it very well.
In the official example, when using group by time(12m)=, the time boundary is 00:12, 00:24. When using group by time(30m), the time boundary becomes 00:00, 00:30. It seems that the time boundary start from the nearest hour plus x times time interval, that’s not correct. If you using group by time(7m), the returned time boundary is not 00:07, 00:14
Here a example:
If the data is:
{'time': '2020-01-01T00:02:00Z', 'value': 10}
{'time': '2020-01-01T00:04:00Z', 'value': 8}
{'time': '2020-01-01T00:05:00Z', 'value': 21}
{'time': '2020-01-01T00:07:00Z', 'value': 33}
{'time': '2020-01-02T00:05:00Z', 'value': 9}
{'time': '2020-01-03T10:05:00Z', 'value': 4}Execute select sum(value) from data where time>='2020-01-01 00:00:00' and time<'2020-01-04 00:00:00' group by time(7m) fill(none) will output:
{'time': '2019-12-31T23:58:00Z', 'sum': 18}
{'time': '2020-01-01T00:05:00Z', 'sum': 54}
{'time': '2020-01-02T00:00:00Z', 'sum': 9}
{'time': '2020-01-03T10:04:00Z', 'sum': 4}Note that the time boundary begins at 12-31 23:58, not 01-01 00:00. What cause this?
InfluxDB using timestamp 0 (1970-01-01T00:00:00Z) as start time, and for each timestamp that is dividable by the group by interval, it create a boundary. So in this sql, the boundary should be timestamp 0, timestamp 420, timestamp 840 etc. 2019-12-31 23:58:00 convert to timestamp 1577836680, it’s dividable by 420, so this is the nearest time boundary among the given data.
When you use gourp by time(1w), you will also meet this problem: the result time begins with Thursday rather than Monday. As 1970-01-01 is Thursday.
So when you use group by time statement, you’d better use 30s, 1m, 5m, 10m as interval, which are factors of 1h, so the result always begin at xx:00.
Some times you want to calculate the sum of last recent 5m data every minute, by using group by time(5m), you only get 1 result every 5 minute. To achieve this, you can use the offset parameter in group by time statement. For example, group by time(5m,1m) with move the time boundary 1 minute forward, the result will be xx:01, xx:06. you can create 5 continuous queries with offset from 0 to 4.
More example can be found in this repo.
Group by in Continuous Queries
By reading the official resample document, the resample every <interval> for <interval> can override the continuous queries execute interval and the time range of query statement.
The example in official document the interval is always a multiple of group by time(m). I tries different values, here is the result.
Every Interval
every interval can be any value regardless of group by time interval. The CQ will execute at the time boundary of every interval.
For Interval
for interval can be greater or equal to group by time(xx). If it is less than group by interval, influx will raise an error like this: ERR: error parsing query: FOR duration must be >= GROUP BY time duration: must be a minimum of 20s, got 5s
Start Time and End Time in CQs
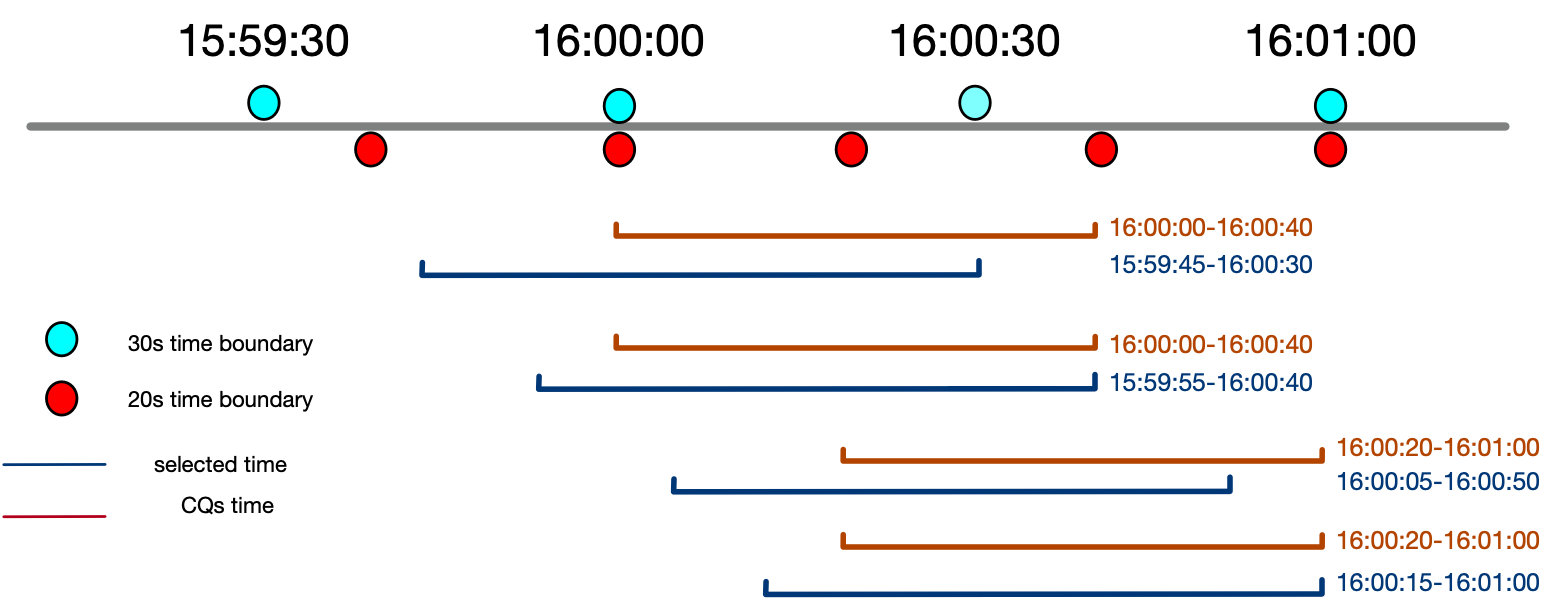
Here is a simple example, every 10 s for 45s group by time(20s)
| execute time | selected start time | selected end time | real start time | real end time |
|---|---|---|---|---|
| 16:00:30 | 15:59:45 | 16:00:30 | 16:00:00 | 16:00:40 |
| 16:00:40 | 15:59:55 | 16:00:40 | 16:00:00 | 16:00:40 |
| 16:00:50 | 16:00:05 | 16:00:50 | 16:00:20 | 16:01:00 |
| 16:01:00 | 16:00:15 | 16:01:00 | 16:00:20 | 16:01:00 |
We can see that, the execute interval is always 10s, but the start time and end time in CQ not equals to now()-45s-now(). It still based on group by time’s time boundary, but the start time must >= selected start time and end time is also >= selected end time.
Here is another example, every 5s for 10s group by time(10s)
| execute time | selected start time | selected end time | real start time | real end time |
|---|---|---|---|---|
| 16:00:00 | 15:59:50 | 16:00:00 | 16:59:50 | 16:00:00 |
| 16:00:05 | 15:59:55 | 16:00:05 | 16:00:00 | 16:00:10 |
| 16:00:10 | 16:00:00 | 16:00:10 | 16:00:00 | 16:00:10 |
| 16:00:15 | 16:00:05 | 16:00:15 | 16:00:10 | 16:00:20 |
I guess the reason why start time is always >= selected start time is to prevent pollute previous data. If the aggregated data is not enough, it will overwrite the correct data generated before. If there is not enough data in end time clause, it will be correct in the future.