Using Dueling DQN to Play Flappy Bird
Table of Contents
PyTorch provide a simple DQN implementation to solve the cartpole game. However, the code is incorrect, it diverges after training (It has been discussed here).
The official code’s training data is below, it’s high score is about 50 and finally diverges.
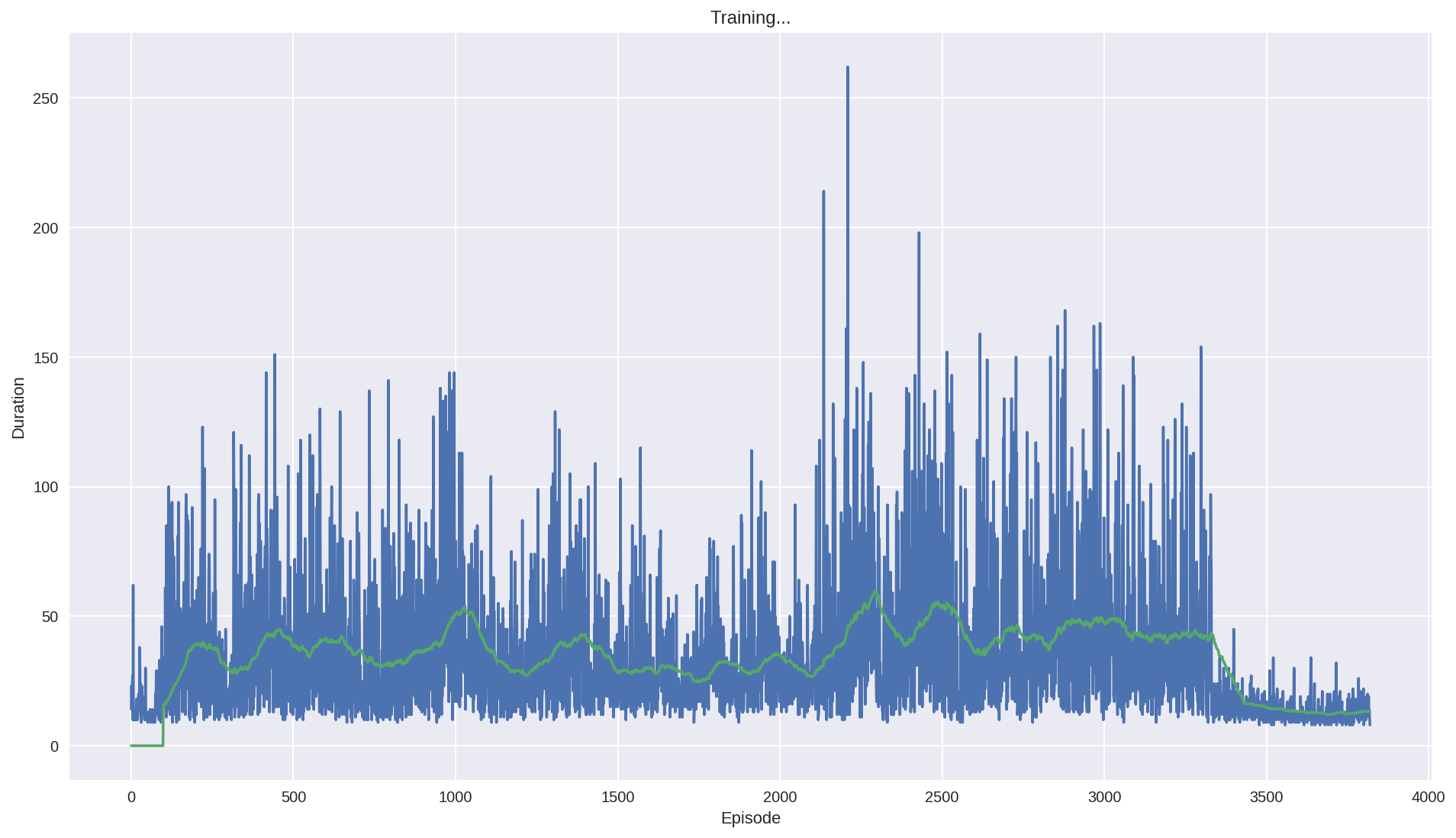
There are many reason that lead to divergence.
First it use the difference of two frame as input in the tutorial, not only it loss the cart’s absolute information(This information is useful, as game will terminate if cart moves too far from centre), but also confused the agent when difference is the same but the state is varied.
Second, small replay memory. If the memory is too small, the agent will forget the strategy it has token in some state. I’m not sure whether 10000 memory is big enough, but I suggest using a higher value.
Third, the parameters. learning_rate, target_update_interval may cause fluctuation. Here is a example on Stack Overflow. I also met this problem when training cartpole agent. The reward stops growing after 1000 episode.
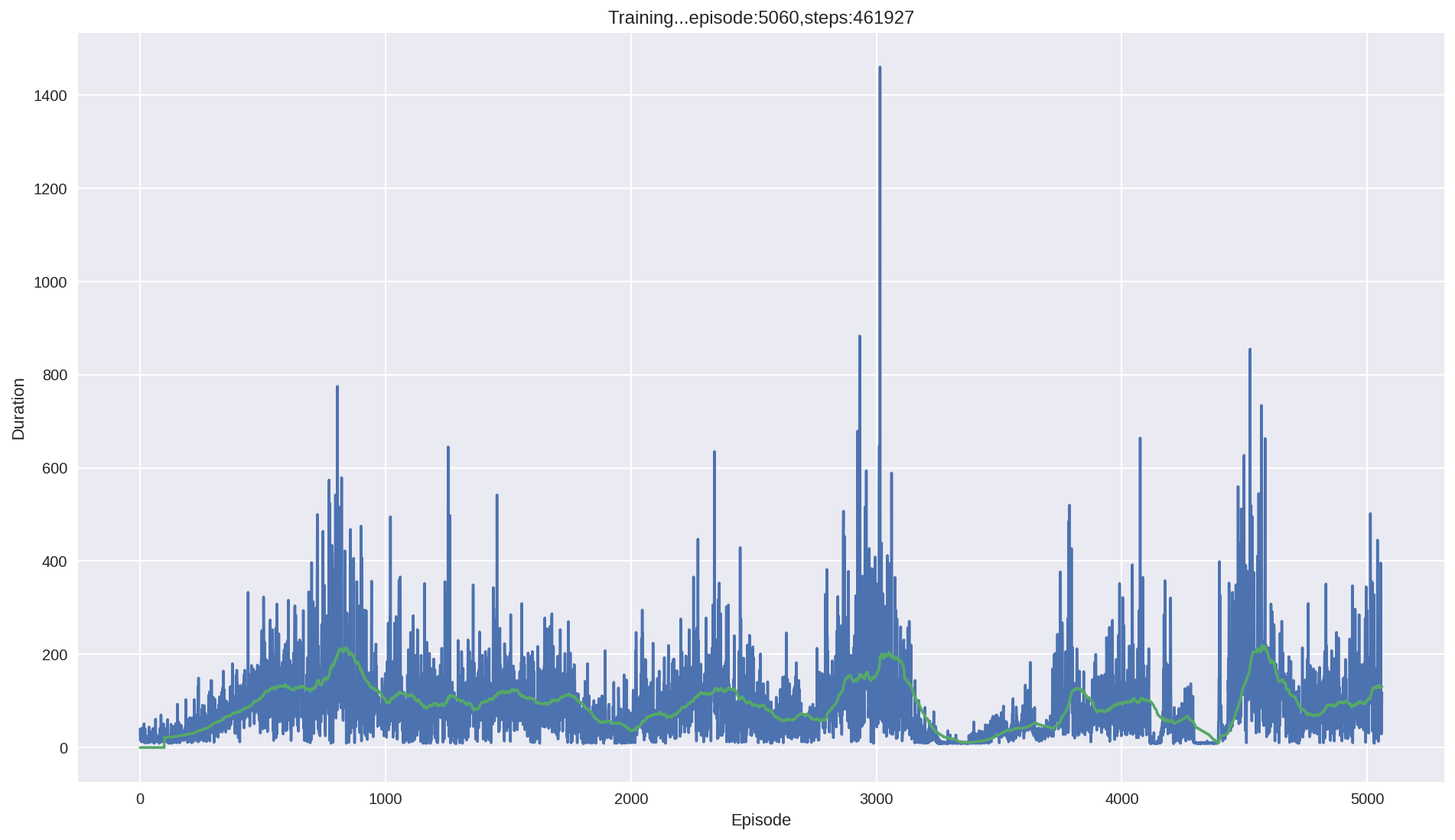
After doing some research on the cartpole DNQ code, I managed to made a model to play the flappy bird. Here are the changes from the original cartpole code. Most of the technology can be found in these two papers: Playing Atari with Deep Reinforcement Learning and Rainbow: Combining Improvements in Deep Reinforcement Learning.
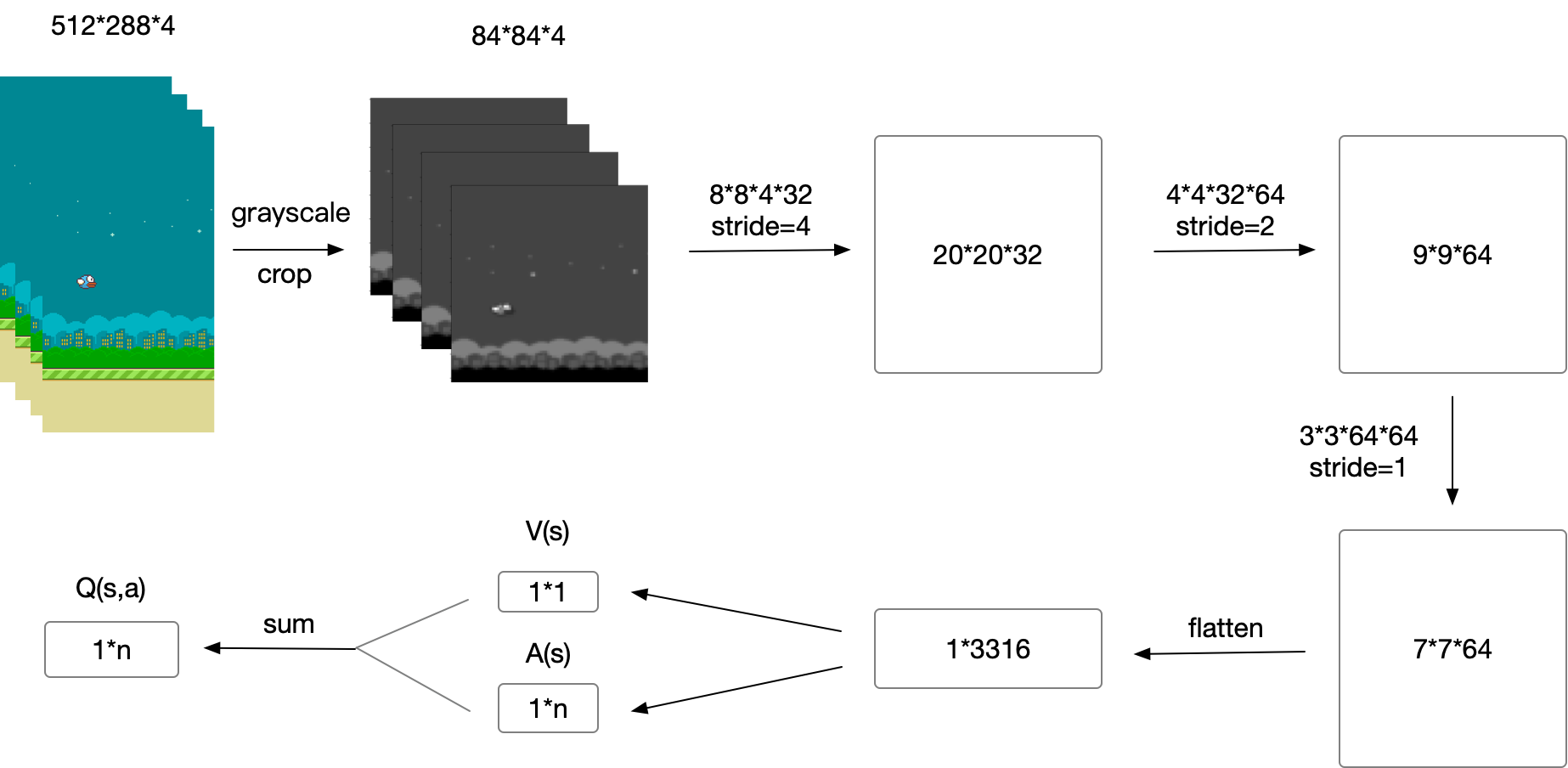
Here is the model architecture:
Here is a trained result:
{{< youtube NV82ZUQynuQ >}}
Dueling DQN
The vanilla DQN has the overestimate problem. As the
maxfunction will accumulate the noise when training. This leads to converging at suboptimal point. Two following architectures are submitted to solve this problem.\[ Q(s, a) = r + \gamma \max_{a’}[Q(s’, a’)] \]
Double DQN was published two year later DQN. It has two value function, one is used to choose the action with max Q value, another one is used to calculate the Q value of this action.
\[ a^{max}(S’_j, w) = \arg\max_{a’}Q(\phi(S’_j),a,w) \]
\[ Q(s,a) = r + \gamma Q’(\phi(S’_j),a^{max}(S’_j, w),w’) \]
Dueling DQN is another solution. It has two estimator, one estimates the score of current state, another estimates the action score.
\[Q(s, a) = r + \gamma( \max_{a’}[A(s’,a’)+V(s’)]\]
In order to distinguish the score of the actions, the return the Q-value will minus the mean action score:
x=val+adv-adv.mean(1,keepdim=True)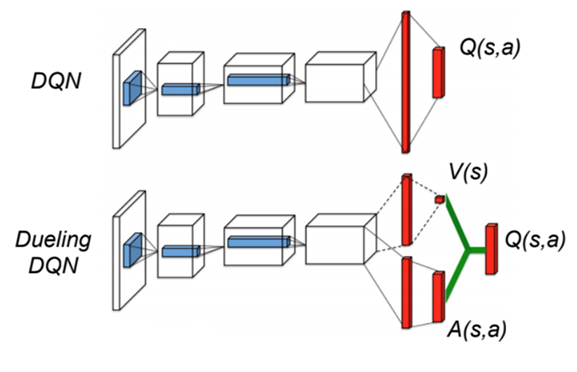
In this project, I use dueling DQN.
Image processing
I grayscale and crop the image.
Stack frames
I use the last 4 frame as the input. This should help the agent to know the change of environment.
Extra FC before last layer
I add a FC between the image features and the FC for calculate Q-Value.
Frame Skipping
Frame-skipping means agent sees and selects actions on every k frame instead of every frame, the last action is repeated on skipped frames. This method will accelerate the training procedure. In this project, I use
frame_skipping=2, as the more the frame skipping is, the more the bird is likely to hit the pipe. And this method did help the agent to converge faster. More details can be found in this post.Prioritized Experience Replay
This idea was published here. It’s a very simple idea: replay high TD error experience more frequently. My code implementation is not efficient. But in cartpole game, this technology help the agent converge faster.
Colab and Kaggle Kernel
My MacBook doesn’t support CUDA, so I use these two website to train the model. Here are the comparison of them. During training, Kaggle seems more stable, Colab usually disconnected after 1h.
Colab Kaggle Kernel GPU Tesla T4(16G) Tesla P100(16G) RAM 13G 13G Max training time 12h 9h Export trained model Google Drive -
The lesson I learnt from this project is patience. It takes a long time(maybe hundreds of thousand steps) to see whether this model works, and there are so many parameters can effect the final performance. It takes me about 3 weeks to build the final model. So if you want to build your own model, be patient and good luck. Here are two articles talking about the debugging and hyperparameter tuning in DQN:
Here are something may help with this task.
It’s a visualization tool made by TensorFlow Team. It’s more convenient to use it rather than generate graph manually by matplotlib. Besides
rewardandmean_q, these variable are also useful when debugging: TD-error, loss and action_distribution, avg_priority.Advanced image pre-processing
In this project, I just grayscalize the image. A more advance technology such as binarize should help agent to filter unimportant detail of game output.

In Flappy Bird RL, the author extract the vertical distance from lower pipe and horizontal distance from next pair of pipes as state. The trained agent can achieve 3000 score.

Other Improvements
Rainbow introduce many other extensions to enhance DQN, some of them have been discussed in this post.
I’ve uploaded code to this repo.
Ref #
- PyTorch REINFORCEMENT LEARNING (DQN) TUTORIAL
- 强化学习 (A series of Chinese post about reinforcement learning)
- Deep Reinforcement Learning for Flappy Bird
- Flappy-Bird-Double-DQN-Pytorch
- DeepRL-Tutorials
- Speeding up DQN on PyTorch: how to solve Pong in 30 minutes
- Frame Skipping and Pre-Processing for Deep Q-Networks on Atari 2600 Games
- OpenAI Baselines: DQN
- Deep-Reinforcement-Learning-Hands-On
- DQN solution results peak at ~35 reward
Update 26-04-19
Colab’s GPU has upgrade to Tesla T4 from K80, now it becomes my best bet.
Update 07-05-19
TensorBoard is now natively supported in PyTorch after version 1.1
Update 26-07-19
If you run out of RAM in Colab, it will show up an option to double the RAM.
Update 13-08-19
Upload video, update code.